Codierverfahren für Audiosignale, zu denen Sprachsignale zählen, sind in der Informationstechnik wichtig für die Übertragung und Aufzeichnung. Codierung bedeutet zunächst, daß das von Natur aus kontinuierliche, `analoge' Schallsignal vorübergehend in einen Strom von diskreten, `digitalen' Daten gewandelt wird. Um teure Übertragungs- und Speicherkapazität einzusparen, befreit man den Strom mit Hilfe von Rechenverfahren von redundanten und irrelevanten Daten. Die vorliegende Arbeit befaßt sich mit den Grundlagen und der Anwendung eines speziellen Rechenverfahrens, das sich an einem Modell der Informationsverarbeitung im menschlichen Gehör orientiert. Eine solche Orientierung hilft, diejenigen Daten auszuwählen, die für den Zuhörer wesentlich sind.
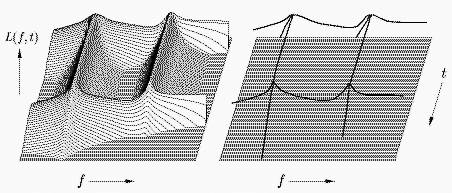
Bild 1: Konturierung des Spektrogramms entspricht geometrisch etwa der Reduktion eines `Pegelgebirges' L(f,t), dargestellt über der Zeit t und der Frequenz f (links), auf seine `Gratlinien' (rechts). Das zugrunde liegende Signal setzt sich aus zwei Sinustönen unterschiedlicher Frequenz zusammen, die gleichzeitig ein- und wieder ausgeschaltet werden.
Ähnlich einem Prisma zerlegt die Basilarmembran im Innenohr das Schallsignal in seine spektralen Bestandteile. Beispielsweise werden Sinustöne verschiedener Frequenz, wenn auch verschwommen, auf verschiedene Orte der Membran abgebildet. Das Ergebnis dieses Vorgangs nähert ein spezielles Spektrogramm an, das man sich nach Bild 1 als `Gebirge' vorstellen kann. Seine Grundfläche wird durch eine Zeit- und eine Frequenzachse aufgespannt, seine Höhe gibt den Energiedichtepegel des Signals über diesen beiden Dimensionen wieder. Konturierung des Spektrogramms bedeutet näherungsweise, daß nur noch die `Gratlinien' des Gebirges verarbeitet werden, wie in Bild 1 angedeutet. Die zeitparallelen Konturlinien geben scharf die hörbaren Sinustöne im Signal wieder, die sich vorher im Spektrogramm wie auch auf der Basilarmembran nur verschwommen abzeichneten.
Die Grundlage für ein solches Verarbeitungsprinzip stammt aus einem Modell der Informationsaufnahme durch das Gehör nach Terhardt . Dort stellt sich der Hörvorgang als eine hierarchische Anordnung von autonomen Entscheidungsprozessen dar, welche als Konturierungsvorgänge realisiert werden. Der Begriff `Konturierung' ist dabei in Anlehnung an den visuellen Begriff als `Reduktion auf das Wesentliche' zu verstehen. Den elementarsten Entscheidungsprozeß verkörpert die Konturierung des Spektrogramms, dessen spezielle Gehöranpassung eine wichtige Rolle spielt. Es wird über die von Terhardt vorgeschlagene Fourier-t-Transformation (FTT) gewonnen, einer Kurzzeitspektraltransformation, die eine frequenzabhängige Analysebandbreite aufweist.
Daß sich bestimmte Konturen eines FTT-Spektrogramms zur gehörorientierten Signalrepräsentation eignen, konnte bereits Heinbach mit seinem Teiltonzeitmuster(TTZM)-Verfahren zeigen. Teiltöne entsprechen darin lokalen Maxima in Schnitten parallel zur Frequenzachse, die in ihrer zeitlichen Entwicklung verfolgt werden. Damit sind solche `Gratlinien' erfaßt, die nicht parallel zur Frequenzachse verlaufen und die später als Frequenzkonturen bezeichnet werden. Um das Signal zurückzugewinnen, werden sie als zeitvariante Sinustöne interpretiert und überlagert. Hierin besteht eine entfernte Verwandtschaft zu sogenannten Sinustonrepräsentationen, die sich aber nicht am Gehör orientieren. Das rekonstruierte Signal klingt im großen und ganzen wie das Original, auch wenn die Qualität nicht als Grundlage für hochqualitative Sprachcodierung ausreicht. Heinbach stellte auch Verfahrensvarianten vor, die das Teiltonzeitmuster mit Hilfe von einfachen Maßnahmen auf wenige, wesentliche Teiltöne reduzieren. Sie erzielen Datenraten bis herab zu etwa 4 kbit/s. Die Verständlichkeit von Sprache wird dabei nicht sonderlich beeinträchtigt, ihre Qualität sinkt allerdings auf ein wenig akzeptables Niveau.
Anfänglich bestand das Ziel der Arbeit darin, aus den Heinbachschen Verfahrensansätzen ein Sprachcodierverfahren mit niedriger Datenrate und akzeptabler Qualität zu entwickeln. Bald zeigte sich jedoch, daß Teiltöne alleine wenig geeignet sind, um alle wahrnehmbaren Sprachanteile datenreduziert zu repräsentieren. Auf der anderen Seite gab es auch keine befriedigende Erklärung, warum selbst ohne Datenreduktion des Teiltonzeitmusters wahrnehmbare Verfälschungen auftreten. Aus dieser Situation heraus schien es fruchtbarer, das TTZM-Verfahren zu analysieren und zu überarbeiten. Daraus wurde die Vorstellung von erweiterten Signalrepräsentationen entwickelt, die sich weiterhin an den Prinzipien des Terhardtschen Modells orientieren. Im Mittelpunkt steht die `Gratlinien'-Repräsentation des FTT-Spektrogramms, mit der prinzipiell hochqualitative Audiocodierung erreichbar ist. Auf dieser erweiterten Grundlage wurde schließlich erneut eine datenreduzierende Sprachcodierung angestrebt. Die Arbeit ist folgendermaßen angelegt:
Zusammenfassung aller wesentlichen Ergebnisse
$Id: ein0.html,v 1.1 1998/03/15 06:44:00 mummert Exp mummert $